Guest blog by Jonas Vandenbruaene is a business-engineering student at the University of Antwerp
Nowadays everyone is talking about data & analytics. Executives are figuring out how to turn it into value, researchers are writing huge amounts of papers about it and students are enrolling in massive numbers in data science programs.
This would lead to believe that data & analytics are a recent phenomenon. And indeed, there are convincing reasons that show analytics is more important and relevant than ever. However, the underlying idea of analytics- the urge to understand the nature of our reality and to act accordingly- is as old as humanity itself.
What’s even more surprising is that people seem to have solved an enormous big data problem several millennia ago. To see how, let us summarize a chapter from Yuval Noah Harari’s great book ‘A Brief History of Humankind’.
Memory Overload
For millennia our ancestors have been living as foragers hunting for animals and looking for sweet berries. At this point in history data was already crucial. If you always forgot that snakes are dangerous and red mushrooms are poisonous your chances of survival were slim. Luckily, the amount of important data was small so people could store everything they needed to know in their brains. However, when humans started living in bigger settlements and communities the limits of our brainpower became painfully obvious.
Living in these larger societies required an entirely different mental skillset. Many problems that arose were data related and could not be solved with the conventional technique of the day: memorization. For example, local rulers had to know how much grain they had in their inventories and whether it was enough to survive the winter. There were taxes to be collected from thousands of inhabitants and thus payment data that had to be stored. There were legal systems that had to handle property data and ever growing families that had to keep track of their family tree. There was just so much more data around than before that just learning everything by heart, like we had been doing for millennia, was never going to work out.
What we needed was a quantum leap. Thus our ancestors conceived a genius system roughly 5000 years ago that encoded their thoughts into abstract symbols, which in turn could be interpreted by others who were familiar with the rules of this system. This made storing and processing information outside early humans’ brains possible for the first time ever. Writing was born.
.jpg)
Figure 1: early writing on clay tablets, Mesopotamia 3000 BC
Big data 2.0
It is astonishing how closely these data issues in early human civilizations are related to the current struggle of companies and governments to store and process evermore data.
Today, the total amount of data is increasing at the astonishing rate of 40% per year as depicted in figure 2.
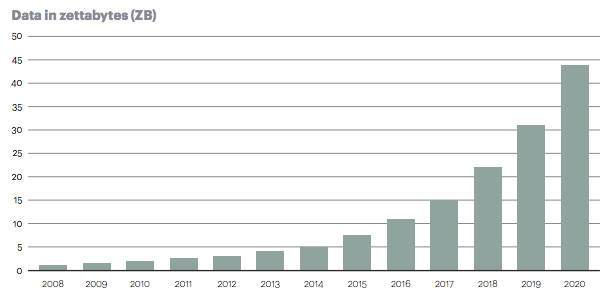
Figure 2: total amount of data in ZB
To get a sense of how huge this is, let’s consider the following statistics:
- In 2015, 205 billion emails were sent every day!
- In 2016, 432,000 hours of video were uploaded on YouTube, every day!
- By 2020, more than 6GB of data will be created every hour for every human being on the planet!
This incredible amount of data can be of tremendous value for a company if it knows how to extract information from it. However, researchers estimate only 0.5% of all data is ever analyzed. Clearly, there is a vast ocean of undiscovered data waiting to be analyzed and turned into value.
Just like 5000 years ago, when simple memorization was not longer able to store and analyze data efficiently, companies today are witnessing their traditional analytics systems are not longer effective to tame the big data tsunami.
Just like memorization was replaced by writing, traditional databases are replaced by distributed systems. The quantum leap necessary to make data analytics on a vast scale possible.
Conclusion
Big data turns out to be a 5000-year-old problem! The big data architect could turn out to be the second oldest profession after all…